Veo 3.1 Ingredients to Video:複数の参照画像を1本のAIクリップに合成する(2026)
Veo 3.1 ingredients to video:人物・オブジェクト・シーンの最大3枚の参照画像を1本の一貫したAIクリップに合成。手順、プロンプト、単一参照や frames to video との違いを解説。
Emma Chen · 3 min read · Jun 29, 2026
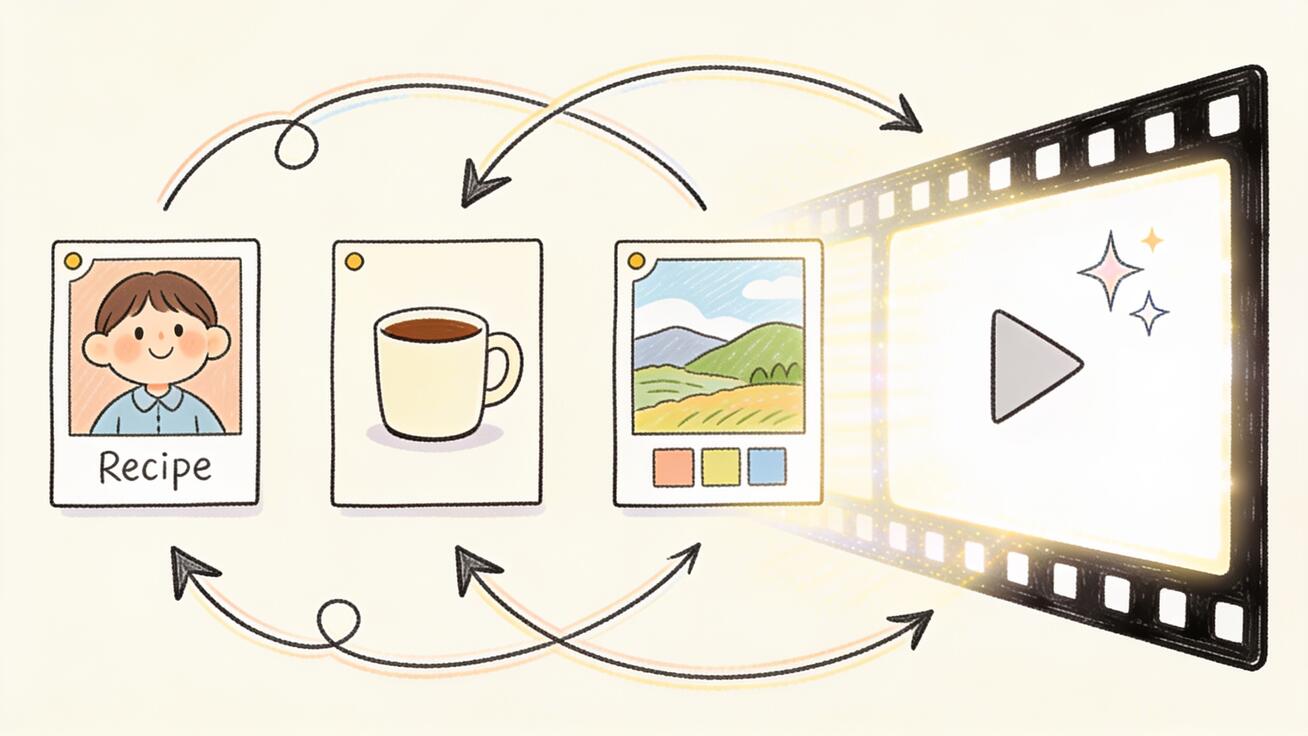
Veo 3.1 ingredients to video は、シーンを言葉で説明するのをやめ、画像から「キャスティング」できるようにする機能です。1枚の参照画像ではなく、人物・オブジェクト・背景・スタイルといった複数の画像を Veo 3.1 に渡すと、モデルがそれらの「材料(ingredients)」を1本のまとまったAIクリップへと溶け込ませます。その結果、誰が画面に映り、何を手に持ち、どこで起きているのかを、テキストプロンプトだけでは決して得られないほど精密に制御できます。
このガイドは、Veo 3.1 で ingredients to video を使うための実践的な手順を最初から最後まで解説します。この機能が実際に何をするのか、参照画像を何枚まで受け付けるのか、単一参照画像や frames to video とどう違うのか、Google Flow や Gemini アプリで今日から実行できる再現性のあるワークフロー、コピーしてすぐ使えるプロンプトテンプレート、最適なユースケース、そしてきれいな合成と濁った合成を分ける品質チェックまでを扱います。すでに veo3ai.io で Veo を使っているなら、これは既存のワークフローにそのまま組み込めます。
クイックアンサー:Ingredients to Video の役割
ingredients to video では、複数の参照画像をアップロードできます。Google のドキュメントと Flow では各画像を「材料(ingredient)」と呼びます。そのうえで、それらを1本の生成クリップへどう組み合わせるかを Veo 3.1 に伝えるプロンプトを書きます。各材料はショットの異なる要素を定義できます。1枚は人物の顔と衣装、1枚は製品や小道具、1枚は場所やビジュアルスタイル、というように。Veo 3.1 はそれらを同時に読み取り、提供した写真と一致した人物・オブジェクト・環境を保つ動画を生成します。
具体的には次のとおりです。
- 1回の生成につき最大3枚の参照画像を提供します(これは Flow、Gemini アプリ、Gemini API における現在の上限です)。
- 各画像が異なる側面を制御します。被写体、オブジェクト、シーン、またはスタイルです。
- 各画像をその役割に明示的に対応づけ、アクションを記述するテキストプロンプトを追加します。
- Veo 3.1 は8秒のクリップを出力します。今ではネイティブな同期音声とセリフが付き、標準の横長に加えて、ソーシャル向けにネイティブの縦型9:16フォーマットにも対応します。
同じ人物が特定の場所で特定の動作をする必要があり、その各要素の参照写真がある場合に使ってください。これこそ、テキストから動画を生成する方式だけでは埋められないギャップです。
Ingredients が単一参照や Frames to Video とどう違うか
ここはほとんどのチュートリアルが飛ばす部分であり、ingredients to video が独立したモードとして存在する理由そのものです。Veo 3.1 には実際、画像で駆動する3つの異なる経路があり、それぞれが異なる課題を解決します。
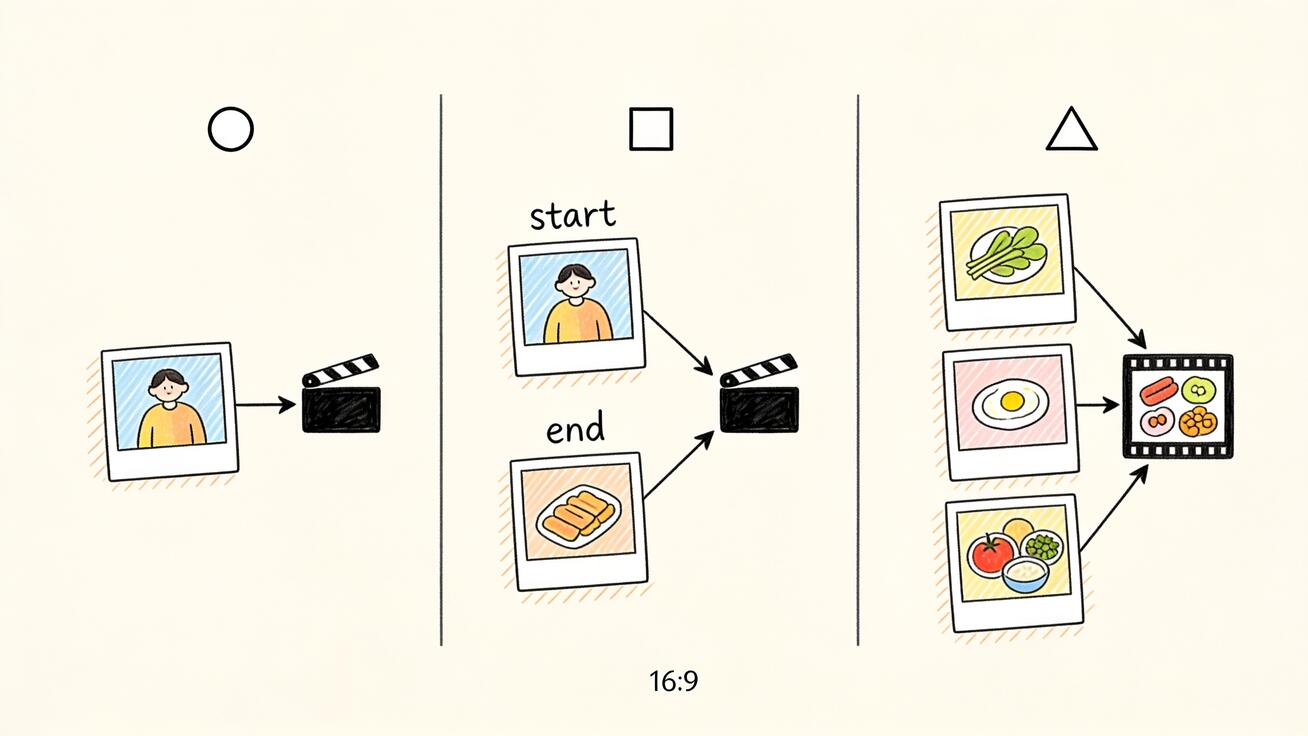
単一参照画像(当社の Veo 3 画像参照ワークフローで解説)は、1枚の画像で1つの対象——通常は人物の顔や製品——を固定し、その周囲に動きを生成します。1人の被写体を複数ショットで一貫させる最速の方法ですが、環境や小道具を別々に制御することはできません。1枚の画像、1つのアンカーです。
Frames to video(当社の Veo 3.1 frames to video ガイドを参照)は、2枚の画像——開始フレームと終了フレーム——を取り、その間の動きを補間します。これはトランジションの話です。モデルが画像Aから画像Bへの橋を時間をかけて構築します。2枚の画像は異なる瞬間の同じシーンであり、異なる要素ではありません。
Ingredients to video は補間ではなく組み合わせです。複数の異なる要素——ここに人物、そこにジャケット、街の通り、フィルムグレインの雰囲気——を与えると、どの1枚の写真にも存在しなかった新しいシーンへと組み立てます。1つのショットの2つの状態を橋渡しするのではなく、複数の被写体と環境を新しいフレームに合成するのです。だからこそ ingredients は「この人物がこの製品を持ってこの場所にいる」に適したツールであり、frames to video は「この冒頭ショットをあの終盤ショットへ変化させる」に適したツールなのです。
Veo と Gemini が各モードで参照画像をどう扱うかの全体像を知りたい場合は、Gemini Omni の画像・動画・音声プロンプトガイドがシステム全体を整理しています。
どこで使えるか
Veo 3.1 の ingredients to video は、Google の各面で利用できます。
- Google Flow — ingredients が Frames や Extend と並ぶ、専用のAI映像制作ツール。
- Gemini アプリ — プロンプト主導の素早い生成向け。
- Google Vids と YouTube — これらの製品内で作業するクリエイター向け。
- Gemini API と Vertex AI — ingredients to video をプログラムから呼び出したい開発者向け(Vertex はモデルIDが文書化された有料プレビューとして提供)。
アップロードのUIは Flow と Gemini アプリで少し異なりますが、基本の流れはどこでも同じです。材料画像を追加し、ラベル付けまたは並べ替えをし、それぞれを参照するプロンプトを書き、生成します。
ステップバイステップ:Veo 3.1 で Ingredients to Video を使う方法
今日から実行できる再現性のある手順です。
ステップ1:3つの材料を計画する
ツールに触れる前に、(最大3枚の)各画像が何を制御するかを決めます。信頼できる分け方は次のとおりです。
- 被写体 — 人物やキャラクター。理想的には、くっきりと十分に照明された顔写真または全身写真。
- オブジェクト — 被写体が関わる製品、小道具、アイテム。
- シーンまたはスタイル — 場所、背景、または色と雰囲気を決める参照フレーム。
3つの枠をすべて使う必要はありません。強くて明確に異なる2枚は、競合する3枚よりも良い結果になることが多いです。制約は上限(3枚)であって、ノルマではありません。
ステップ2:高品質な参照画像を用意する
入力の品質が、そのまま出力の品質を決めます。各材料について次を行います。
- 高解像度でシャープな PNG または JPEG ファイルを使う。
- 1つのシーンに見せたいなら、画像間で照明と角度を一貫させる。
- 要素を切り出す。ポートレートは主に人物、製品写真は主に製品にする。雑然とした背景はモデルを混乱させます。
- きれいな材料を作成する必要があるなら、まず画像モデルで生成する(Google 自身の流れでは、Veo に渡す前に Gemini の画像生成で一貫したキャラクターと設定を作ることを推奨)。
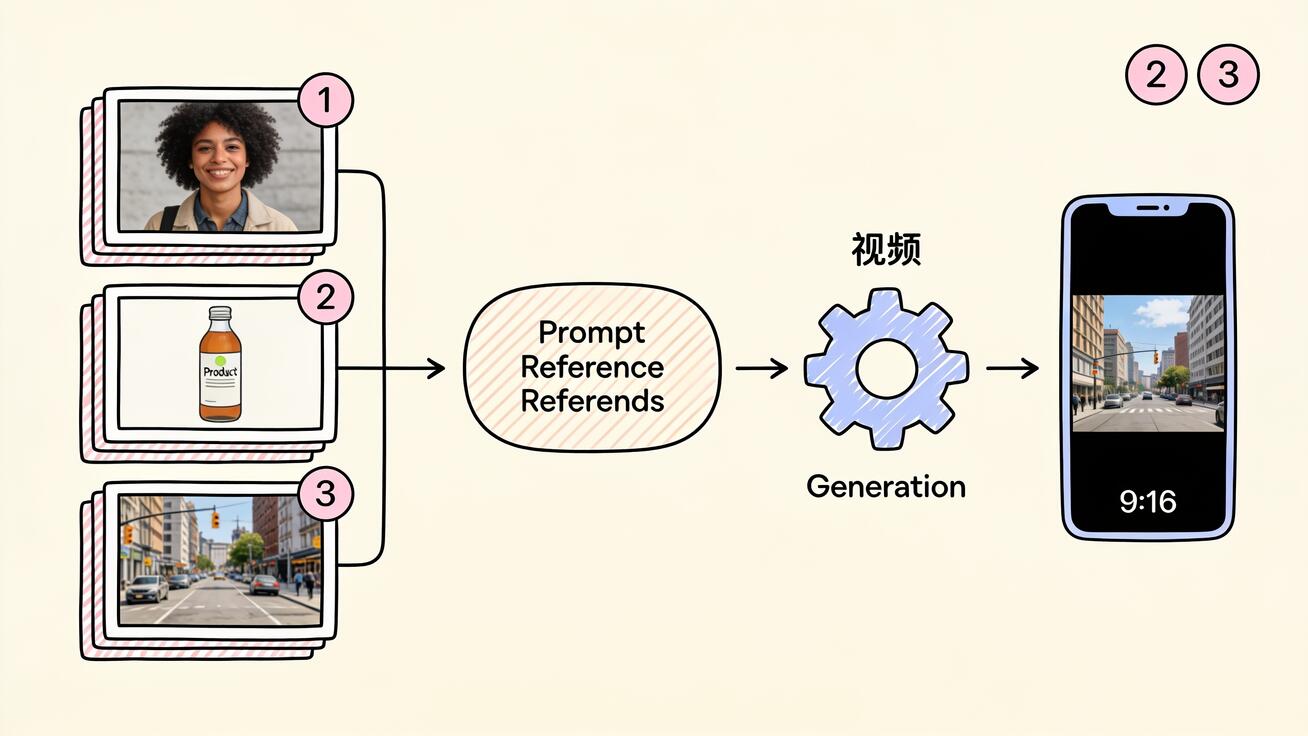
ステップ3:材料を優先順位順にアップロードする
Flow または Gemini アプリで、各参照画像を材料パネルに追加します。順序が重要です。最も重要な要素(通常は人物)を最初に置きます。要素が画面内で注目を奪い合うとき、モデルは先の画像をより高い優先度として扱います。
ステップ4:各画像を役割に対応づけるプロンプトを書く
ここで多くの生成が成功するか失敗するかが決まります。単に「街でコーヒーを飲む女性」と書かないでください。各材料をその仕事に明示的に結びつけます。
「参照画像1の女性が、参照画像2のコーヒーカップを持ち、参照画像3の雨のネオン街を歩く。ゆっくりとしたドリーショット、浅い被写界深度、彼女は微笑んで一口飲む。」
「参照画像1/2/3」と名前を挙げることで、モデルに推測させる代わりに、部品の組み立て方を Veo 3.1 に正確に伝えられます。そのうえで、アクション、カメラの動き、雰囲気を記述します。これらは画像にはなく、テキストから与える必要があります。
ステップ5:フォーマットを設定して生成する
アスペクト比を選びます。Veo 3.1 は今、TikTok、Reels、Shorts 向けのネイティブ縦型9:16に加え、標準の16:9も生成します。8秒のクリップを生成します。ingredients は今ネイティブ音声に対応しているため、同じパスでセリフや環境音をプロンプトすることもできます。
ステップ6:確認し、反復し、延長する
出力を材料と照合します(下の品質チェックリストを参照)。要素がぶれたら、やみくもに再生成するのではなく、プロンプトの表現を調整するか、よりきれいな参照画像に差し替えます。気に入ったクリップができたら、Veo 3.1 の Extend とシーン延長機能で、同じ人物を単一の8秒クリップを越えて、より長くつながったシーケンスへ運べます。
コピーして使えるプロンプトテンプレート
自分の材料に合わせて調整してください。各画像を対応づけ、その後にアクションとカメラを記述するというパターンが、これらを機能させます。
人物+製品配置:
「画像1の人物が、画像3の[場所]で、画像2の[製品]を持って立つ。ミディアムショット、柔らかい窓明かり、彼は製品をカメラへ向けて微笑む。自然な環境音。」
新しいシーンでの人物の一貫性:
「画像1と同じキャラクターが、今は画像2の森の設定にいる。前進する彼を後ろから追うトラッキングショット、午後遅い光、舞い落ちる葉。足音と鳥のさえずり。」
被写体へのスタイル転送:
「画像1の被写体を、画像2の絵画的なビジュアルスタイルでレンダリング。ゆっくりとした押し込み、被写体は見上げ、温かいシネマティックなカラーグレーディング、穏やかなオーケストラの高まり。」
1ショットに2人のキャラクター:
「画像1のキャラクターと画像2のキャラクターが、画像3の内装のカフェのテーブルを挟んで向かい合う。肩越しのショット、二人は笑ってカップを合わせる。カフェの環境音と短いセリフ。」
縦型のソーシャル広告:
「画像1のモデルが、画像2のジャケットを着て、画像3の都会の屋上に立つ。ネイティブ縦型9:16、手持ちの躍動感、彼女はカメラへ一度回転、アップビート。風と街の音。」
最適なユースケース
ingredients to video は、制御された再現可能なキャスティングが必要なあらゆる場面で力を発揮します。
ブランド製品動画。 実際の製品写真、ブランドモデル、ロケ地を1本のクリップに入れ、アイテム・タレント・環境がすべてガイドラインに沿うようにします——撮影なしで。これは EC や DTC チームにとって最も価値の高い用途です。
エピソード全体で一貫したキャラクター。 同じキャラクター材料を再利用し、シーンとオブジェクトの画像を変えることで、複数ショットにわたって同じ主人公を保ちます。これを Veo 3.1 のシーン延長と組み合わせれば、アイデンティティを保ったまま8秒をはるかに超えるシーケンスを構築できます。
縦型のソーシャルファースト広告。 ネイティブ9:16モードと ingredients を合わせれば、顔・衣装・背景があなたの参照に固定された、モデル付き・ロケ付きの TikTok と Reels 向けコンテンツを制作できます。
絵コンテからショットへ。 キャラクターと主要な小道具をすでに静止画として設計しているなら、ingredients はそれらの静的なボードを、すべてをテキストで再記述することなく動きに変えます。
音楽と対話のシーン。 同じ生成内のネイティブ音声により、2人のキャラクター材料のショットが短いセリフを担えるため、1回のパスで会話シーンが可能になります。
品質チェックリスト
ingredients クリップを公開する前に、次のチェックを行ってください。
- アイデンティティの一致 — 生成されたキャラクターは、フレームごとに実際に参照写真に似ていますか。8秒の間の顔のぶれに注意します。
- オブジェクトの忠実度 — 製品や小道具は、形・色・ロゴが正しい本物ですか。生成モデルはオブジェクトを微妙に作り変えることがあります。
- シーンの整合性 — 環境はシーン材料と一致し、被写体の照明は場所の照明と合っていますか。
- 要素のにじみ — ある材料の一部が別の材料に漏れ出ていないか確認します(例:ジャケットの色が背景を染める)。
- テキストと手 — 製品上のテキストと被写体の手を確認します。依然としてAI動画で最も多い失敗箇所です。
- 音声の同期 — セリフをプロンプトした場合、口の動きと音が合っているか確認します。
チェックに失敗したら、まず入力を直します。よりきれいで分離された参照画像のほうが、同じプロンプトでもう一度サイコロを振るよりも多くの問題を解決します。
知っておくべき実際の制約
ingredients to video は強力ですが魔法ではありません。期待は正直に保ちましょう。
- 参照は3枚が上限。 10個の要素を合成することはできません。最も重要な3つを選び、残りはプロンプトに任せます。
- 生成1回につき8秒。 より長い物語には、単一クリップではなく Extend やシーン延長のパスが必要です。
- 競合する参照はぼやける可能性。 2枚の画像が同じ役割を奪い合うと(2つの顔がどちらも「主要被写体」と読まれるなど)、結果が一貫しなくなります。順序とプロンプトの明確さが重要です。
- 完璧なアイデンティティは保証されません。 Veo 3.1 の類似度は高いものの、速い動きや極端な角度ではなおぶれることがあります。各クリップを確認してください。
- 提供状況と料金は異なります——Flow、Gemini アプリ、API の各層で違い、Vertex AI は一部機能を有料プレビューとして提供します。
これらはどれも機能を避ける理由ではありません。3つの材料を意図的に計画し、出力を確認する理由です。
Veo 3.1 ワークフローへの組み込み方
ingredients to video は、タスクに応じて使い分ける3つの画像駆動モードの1つです。
- 被写体を1つだけ固定すればよいときは単一参照画像を使います。画像参照ワークフローから始めてください。
- 開始と終了が決まっていてトランジションが欲しいときは frames to video を使います。frames to video ガイドが最初から最後まで案内します。
- 複数の異なる要素を1つの新しいシーンに組み合わせるときは ingredients to video を使います。
多くの実プロジェクトは3つすべてを使います。キャラクターと小道具を材料として作り、中心ショットを生成し、次に frames to video で次の場面へきれいに切り替え、Extend でシーケンスを延ばします。Google の各面で実行することも、veo3ai.io を通じて1つのパイプラインの一部として実行することもできます。
避けるべきよくある間違い
ingredients の残念な結果のほとんどは、いくつかのパターンが原因です。何に注意すべきかが分かれば、どれも簡単に修正できます。
雑然とした参照画像。 人物写真に強い背景、2人目の人物、目立つロゴが写り込んでいると、Veo 3.1 はどの部分が「材料」なのか分かりません。各画像が1つの要素を明確に表すよう、しっかりトリミングします。
画像を無視したプロンプト。 3枚の参照をアップロードしておきながら「シネマティックなシーン」のような一般的なプロンプトを書くと、機能全体が無駄になります。プロンプトは画像を名指しし、役割を割り当てる必要があります。
矛盾する照明。 平坦なスタジオ照明で撮った被写体を暗い夜のシーンに落とし込むと、貼り付けたように見えます。照明がすでにおおよそ一致する材料を選ぶか、望む照明を明示的にプロンプトしてください。
枠の詰め込みすぎ。 主役を奪い合う3枚の参照は、ぐちゃぐちゃになります。多くの場合、補完し合う強い2つの材料のほうが、よりきれいで制御しやすい結果になります。
入力での反復を飛ばすこと。 クリップがぶれると、同じ設定で再生成したくなります。多くの場合、よりシャープな参照画像に差し替えるか、プロンプトの1行を引き締めるほうが良い手です。
FAQ
Veo 3.1 の ingredients to video は参照画像を何枚まで使えますか。 最大3枚です。各画像が異なる要素——被写体、オブジェクト、またはシーン/スタイル——を制御でき、競合するときは優先順位順に並べます。
ingredients to video は1枚の参照画像をアップロードするのと違いますか。 はい。単一参照は1つの被写体を固定します。ingredients は複数の異なる要素(人物+オブジェクト+シーン)を1本のクリップに合成します。解決する課題が異なります。
ingredients to video は音声を含みますか。 はい。Veo 3.1 のアップデートでネイティブな同期音声とセリフが追加され、ingredients の生成は同じパスで音声を含められます。
縦型動画は作れますか。 はい。Veo 3.1 は ingredients 向けにネイティブ縦型9:16フォーマットを追加し、標準の16:9に加えて、TikTok、Reels、Shorts のようなモバイルファーストのプラットフォームに最適化されています。
どこで利用できますか。 Google Flow、Gemini アプリ、Google Vids、YouTube、そして Gemini API と Vertex AI を通じてプログラムからも利用できます。
各クリップの長さは。 各生成は8秒のクリップを出力します。より長いコンテンツには、Veo 3.1 の Extend とシーン延長機能を使い、つながったセグメント全体でキャラクターを一貫させます。
まとめ
Veo 3.1 ingredients to video は、AIクリップの中で誰が・何を・どこでを同時に制御する、最も直接的な方法です。人物に1枚、オブジェクトに1枚、シーンやスタイルに1枚——最大3枚の参照画像をモデルに与え、各画像を役割に対応づけるプロンプトを書くことで、テキストプロンプトや単一参照画像では到底作れない、合成され一貫したショットが得られます。これは2つのキーフレームを橋渡しする frames to video とも、被写体を1つだけ固定する単一参照とも異なります。3つの材料を計画し、きれいな入力を用意し、役割ごとにプロンプトし、各クリップを確認してください。そして veo3ai.io の Veo 3.1 で自分でこの流れを試し、参照写真を動くシーンに変えましょう。
Related Articles
Continue with more blog posts in the same locale.
Veo 3.1 動画の長さはどれくらい?最大時間と長さ制限を解説(2026)
Veo 3.1 のクリップは1生成8秒が上限ですが、延長で約148秒まで到達できます。ネイティブの長さ、Fast vs Quality、video-to-video のルール、FAQ。
Read article
Veo 3 スローモーション動画プロンプト(2026年版):映画的スローモーとスピードランプ
Veo 3 でスローモーションを使いこなす:プロンプト語彙、すぐ使える7つのプロンプト、スピードランプ、音声の扱い、よくある失敗。
Read article
Veo 3のPOV動画プロンプト:一人称視点ショットの生成方法(2026年版)
Veo 3で没入感のある一人称POV動画を作るプロンプトの書き方:5部構成の公式、すぐ使える12の例、同期音声のコツ、TikTok・Shorts向け縦型ワークフロー。
Read article