Veo 3.1 Ingredients to Video : combiner plusieurs images de référence en un seul clip IA (2026)
Veo 3.1 ingredients to video : combinez jusqu'à trois images de référence — personnage, objet et scène — en un seul clip IA cohérent. Flux pas à pas, prompts et différences avec la référence unique et frames to video.
Emma Chen · 15 min read · Jun 29, 2026
Veo 3.1 ingredients to video est la fonctionnalité qui vous permet d'arrêter de décrire une scène avec des mots pour commencer à la composer à partir d'images. Au lieu d'une seule image de référence, vous fournissez à Veo 3.1 plusieurs images — un personnage, un objet, un décor, un style — et le modèle fond ces « ingrédients » en un seul clip IA cohérent. Le résultat offre un contrôle bien plus précis sur qui est dans le plan, ce qu'il tient et où tout se déroule que les prompts texte ne pourraient jamais le permettre.
Ce guide est une marche à suivre pratique et complète sur l'utilisation d'ingredients to video dans Veo 3.1 : ce que fait réellement la fonctionnalité, combien d'images de référence elle accepte, en quoi elle diffère de l'image de référence unique et de frames to video, un flux de travail reproductible que vous pouvez lancer dès aujourd'hui dans Google Flow ou l'app Gemini, des modèles de prompts prêts à copier, les meilleurs cas d'usage et les contrôles qualité qui distinguent une composition nette d'une bouillie. Si vous travaillez déjà avec Veo sur veo3ai.io, cela s'intègre directement à votre flux existant.
Réponse rapide : ce que fait Ingredients to Video
Ingredients to video vous laisse téléverser plusieurs images de référence — la documentation de Google et Flow appellent chacune un « ingrédient » — puis écrire un prompt qui indique à Veo 3.1 comment les combiner en un clip généré. Chaque ingrédient peut définir un élément différent du plan : une image pour le visage et la tenue d'un personnage, une pour un produit ou un accessoire, une pour un lieu ou un style visuel. Veo 3.1 les lit toutes en même temps et produit une vidéo où le personnage, l'objet et le décor restent cohérents avec les photos que vous avez fournies.
Concrètement :
- Vous fournissez jusqu'à trois images de référence par génération (c'est le plafond actuel dans Flow, l'app Gemini et l'API Gemini).
- Chaque image contrôle un aspect différent : sujet, objet, scène ou style.
- Vous ajoutez un prompt texte qui associe explicitement chaque image à son rôle et décrit l'action.
- Veo 3.1 produit un clip de 8 secondes — désormais avec son synchronisé natif et dialogue — et prend en charge un format vertical natif 9:16 pour les plateformes sociales, en plus du format horizontal standard.
Utilisez-la quand vous avez besoin du même personnage faisant quelque chose de précis dans un lieu précis, et que vous avez des photos de référence pour chacun de ces éléments. C'est précisément la lacune que la génération de vidéo à partir de texte ne peut pas combler seule.
En quoi Ingredients diffère de la référence unique et de Frames to Video
C'est la partie que la plupart des tutoriels sautent, et c'est toute la raison pour laquelle ingredients to video existe comme mode distinct. Veo 3.1 propose en réalité trois voies différentes pilotées par l'image, et elles résolvent trois problèmes différents.
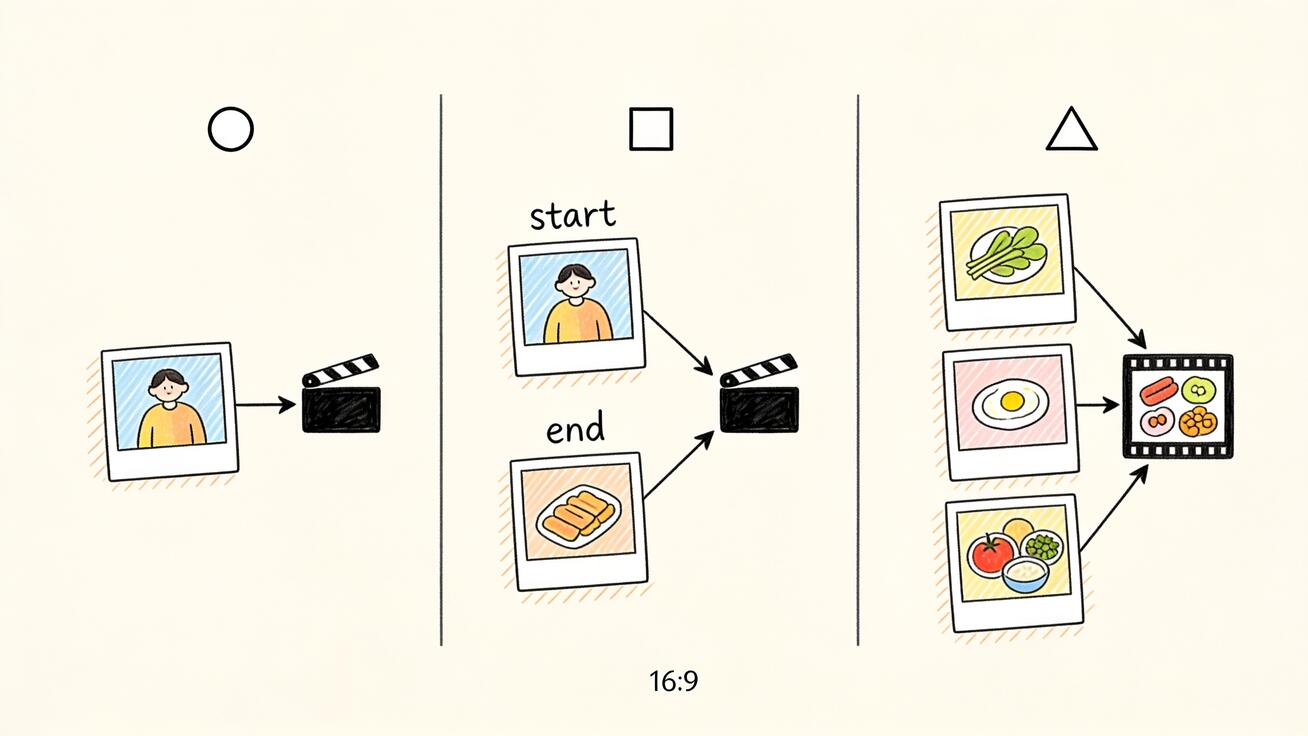
L'image de référence unique (traitée dans notre flux de travail d'image de référence Veo 3) utilise une image pour verrouiller une chose — généralement le visage d'un personnage ou un produit — puis génère du mouvement autour. C'est le moyen le plus rapide de garder un seul sujet cohérent entre les plans, mais il n'offre aucun contrôle séparé sur l'environnement ou les accessoires. Une image, un point d'ancrage.
Frames to video (voir notre guide frames to video de Veo 3.1) prend deux images — une image de début et une image de fin — et interpole le mouvement entre elles. Il s'agit d'une transition : le modèle construit le pont de l'image A à l'image B dans le temps. Les deux images sont la même scène à des moments différents, pas des éléments différents.
Ingredients to video est combinatoire, pas interpolatif. Vous lui donnez plusieurs éléments différents — une personne ici, une veste là, une rue de ville, une ambiance avec grain de pellicule — et il les assemble en une nouvelle scène qui n'existait sur aucune photo isolée. Vous ne reliez pas deux états d'un même plan ; vous composez plusieurs sujets et un décor en une image inédite. C'est pourquoi ingredients est le bon outil pour « place cette personne, tenant ce produit, dans ce lieu », et frames to video est le bon outil pour « transforme ce plan d'ouverture en ce plan de fermeture ».
Si vous voulez la vue d'ensemble de la façon dont Veo et Gemini gèrent l'imagerie de référence à travers les modes, le guide de prompting d'image, vidéo et audio Gemini Omni cartographie tout le système.
Où vous pouvez l'utiliser
Ingredients to video de Veo 3.1 est disponible sur les surfaces de Google :
- Google Flow — l'outil dédié de réalisation de films IA, où ingredients côtoie Frames et Extend.
- L'app Gemini — pour des générations rapides pilotées par prompt.
- Google Vids et YouTube — pour les créateurs travaillant dans ces produits.
- L'API Gemini et Vertex AI — pour les développeurs qui veulent appeler ingredients to video de façon programmatique (Vertex l'expose en préversion payante avec des identifiants de modèles documentés).
L'interface de téléversement diffère légèrement entre Flow et l'app Gemini, mais le principe est partout le même : ajoutez vos images-ingrédients, étiquetez-les ou ordonnez-les, écrivez un prompt qui référence chacune, générez.
Étape par étape : comment utiliser Ingredients to Video dans Veo 3.1
Voici un flux reproductible que vous pouvez lancer dès aujourd'hui.
Étape 1 : planifiez vos trois ingrédients
Avant de toucher à l'outil, décidez ce que chacune de vos (jusqu'à trois) images contrôlera. Une répartition fiable :
- Sujet — le personnage ou la personne, idéalement un portrait net et bien éclairé ou un plan en pied.
- Objet — le produit, l'accessoire ou l'élément avec lequel le sujet interagit.
- Scène ou style — le lieu, l'arrière-plan ou une image de référence qui fixe la couleur et l'ambiance.
Vous n'êtes pas obligé d'utiliser les trois emplacements. Deux images fortes et distinctes valent souvent mieux que trois qui se concurrencent. La contrainte est le plafond (trois), pas un quota.
Étape 2 : préparez des images de référence de qualité
La qualité de l'entrée détermine directement la qualité de la sortie. Pour chaque ingrédient :
- Utilisez des fichiers PNG ou JPEG nets et en haute résolution.
- Gardez un éclairage et un angle cohérents entre les images si vous voulez qu'elles forment une seule scène.
- Isolez l'élément : un portrait doit être surtout la personne, une photo de produit surtout le produit. Les arrière-plans chargés perturbent le modèle.
- Si vous devez créer des ingrédients propres, générez-les d'abord avec un modèle d'image (le propre flux de Google suggère d'utiliser la génération d'images de Gemini pour construire des personnages et décors cohérents avant de les confier à Veo).
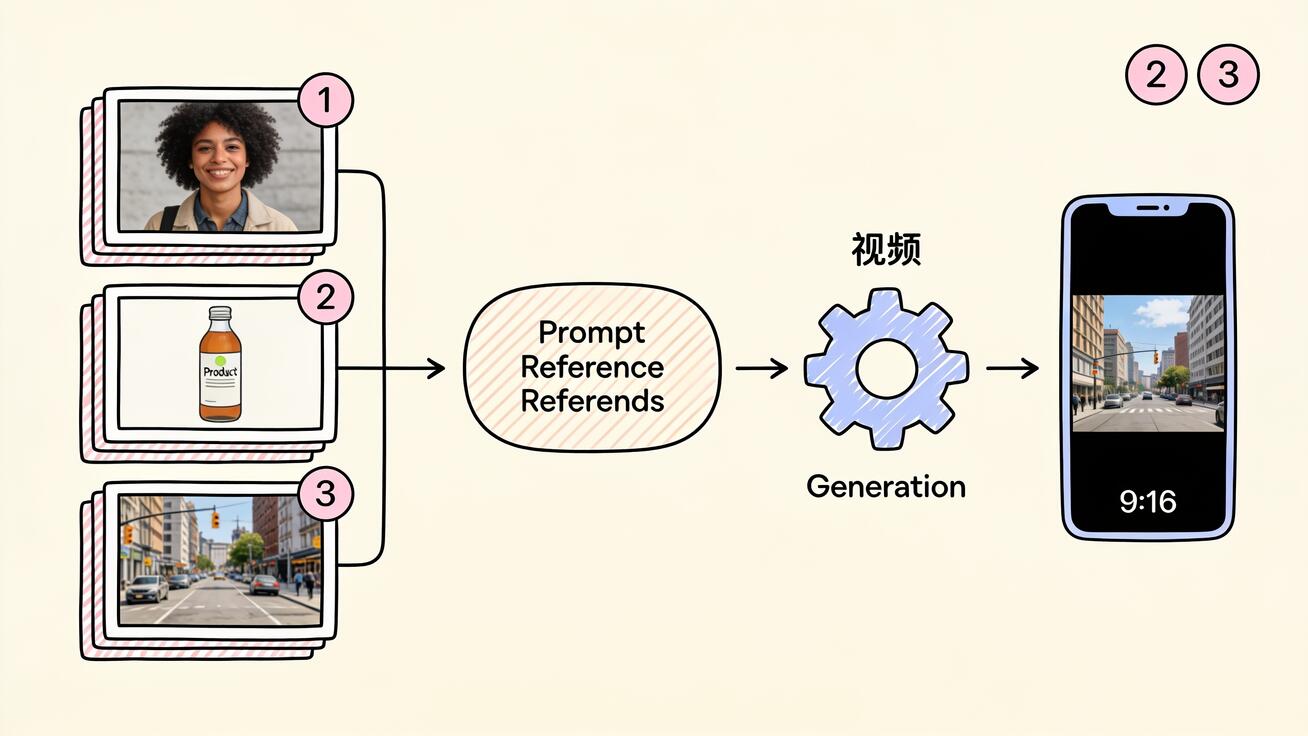
Étape 3 : téléversez vos ingrédients par ordre de priorité
Dans Flow ou l'app Gemini, ajoutez chaque image de référence au panneau d'ingrédients. L'ordre compte : placez l'élément le plus important (en général le personnage) en premier. Le modèle traite les premières images comme plus prioritaires quand les éléments se disputent l'attention dans le plan.
Étape 4 : écrivez un prompt qui associe chaque image à un rôle
C'est ici que la plupart des générations réussissent ou échouent. N'écrivez pas simplement « une femme buvant un café en ville ». Reliez explicitement chaque ingrédient à sa tâche :
« La femme de l'image de référence 1, tenant la tasse de café de l'image de référence 2, marchant dans la rue néon pluvieuse de l'image de référence 3. Travelling lent, faible profondeur de champ, elle sourit et prend une gorgée. »
En nommant « image de référence 1/2/3 », vous dites précisément à Veo 3.1 comment assembler les pièces au lieu de deviner. Décrivez ensuite l'action, le mouvement de caméra et l'ambiance — ils ne sont pas dans vos images et doivent venir du texte.
Étape 5 : choisissez le format et générez
Choisissez votre rapport d'image — Veo 3.1 génère désormais du vertical natif 9:16 pour TikTok, Reels et Shorts, ainsi que le 16:9 standard. Générez votre clip de 8 secondes. Comme ingredients prend maintenant en charge le son natif, vous pouvez aussi demander un dialogue ou un son d'ambiance dans la même passe.
Étape 6 : vérifiez, itérez et prolongez
Comparez la sortie à vos ingrédients (voir la liste de contrôle qualité ci-dessous). Si une pièce dérive, ajustez la formulation du prompt ou remplacez une image de référence plus propre plutôt que de régénérer à l'aveugle. Lorsque vous avez un clip qui vous plaît, les fonctions Extend et d'extension de scène de Veo 3.1 vous permettent de transporter les mêmes personnages au-delà du clip unique de 8 secondes vers des séquences plus longues et connectées.
Modèles de prompts à copier
Adaptez-les à vos propres ingrédients. Le schéma — associer chaque image, puis décrire l'action et la caméra — est ce qui les rend efficaces.
Personnage + placement de produit :
« La personne de l'image 1 tenant le [produit] de l'image 2, debout dans le [lieu] de l'image 3. Plan moyen, lumière douce de fenêtre, elle tourne le produit vers la caméra et sourit. Son d'ambiance naturel. »
Cohérence de personnage dans une nouvelle scène :
« Le même personnage de l'image 1, maintenant dans le décor forestier de l'image 2. Plan en travelling de dos pendant qu'il avance, lumière de fin d'après-midi, feuilles qui dérivent. Bruits de pas et chants d'oiseaux. »
Transfert de style sur un sujet :
« Le sujet de l'image 1 rendu dans le style visuel pictural de l'image 2. Lent travelling avant, le sujet lève les yeux, étalonnage cinématographique chaud, douce montée orchestrale. »
Deux personnages dans un même plan :
« Le personnage de l'image 1 et le personnage de l'image 2 assis de part et d'autre d'une table de café tirée de l'intérieur de l'image 3. Plan par-dessus l'épaule, ils rient et trinquent avec leurs tasses. Ambiance de café et court dialogue. »
Publicité sociale verticale :
« Le mannequin de l'image 1 portant la veste de l'image 2 sur le toit urbain de l'image 3. Vertical natif 9:16, énergie caméra à l'épaule, elle pivote une fois vers la caméra, dynamique. Vent et bruit de rue. »
Meilleurs cas d'usage
Ingredients to video prouve sa valeur partout où vous avez besoin d'un casting contrôlé et reproductible.
Vidéos de produit de marque. Déposez une vraie photo de produit, un mannequin de marque et un lieu dans un seul clip pour que l'article, le talent et l'environnement respectent votre charte — sans tournage. C'est l'usage le plus précieux pour l'e-commerce et les équipes DTC.
Personnages cohérents sur un épisode. Gardez le même protagoniste sur plusieurs plans en réutilisant le même ingrédient-personnage, puis en variant les images de scène et d'objet. Associez cela à l'extension de scène de Veo 3.1 pour bâtir des séquences bien au-delà de huit secondes tout en conservant l'identité.
Publicités social-first en vertical. Le mode 9:16 natif plus ingredients signifie que vous pouvez produire du contenu sur-mannequin et sur-lieu pour TikTok et Reels où le visage, la tenue et l'arrière-plan sont verrouillés sur vos références.
Du storyboard au plan. Si vous avez déjà conçu votre personnage et vos accessoires clés en images fixes, ingredients transforme ces planches statiques en mouvement sans tout redécrire en texte.
Scènes musicales et de dialogue. Avec le son natif dans la même génération, les plans à deux personnages-ingrédients peuvent porter une courte ligne de dialogue, rendant possibles les scènes conversationnelles en une seule passe.
Liste de contrôle qualité
Avant de diffuser un clip ingredients, effectuez ces vérifications :
- Correspondance d'identité — le personnage généré ressemble-t-il vraiment à votre photo de référence, image après image ? Surveillez la dérive du visage sur les huit secondes.
- Fidélité de l'objet — le produit ou l'accessoire est-il le bon, avec la bonne forme, couleur et logo ? Les modèles génératifs peuvent subtilement redessiner les objets.
- Cohérence de la scène — le décor correspond-il à votre ingrédient de scène, et l'éclairage du sujet s'accorde-t-il avec celui du lieu ?
- Débordement d'éléments — assurez-vous que des parties d'un ingrédient ne fuient pas dans un autre (la couleur d'une veste teintant l'arrière-plan, par exemple).
- Texte et mains — vérifiez tout texte sur le produit et les mains du sujet, toujours les points de défaillance les plus fréquents en vidéo IA.
- Synchronisation audio — si vous avez demandé un dialogue, confirmez que le mouvement des lèvres et le son s'alignent.
Si une vérification échoue, corrigez d'abord l'entrée : une image de référence plus propre et plus isolée résout plus de problèmes qu'un nouveau coup de dés sur le même prompt.
Limites réelles à connaître
Ingredients to video est puissant mais pas magique. Gardez des attentes honnêtes :
- Trois références, c'est le plafond. Vous ne pouvez pas composer dix éléments ; choisissez les trois qui comptent le plus et laissez le prompt gérer le reste.
- Huit secondes par génération. Les récits plus longs exigent des passes Extend ou d'extension de scène, pas un seul clip.
- Des références concurrentes peuvent se brouiller. Si deux images se disputent le même rôle (deux visages lus tous deux comme « le sujet principal »), les résultats deviennent incohérents — l'ordre et la clarté du prompt comptent.
- L'identité parfaite n'est pas garantie. La ressemblance dans Veo 3.1 est forte mais peut encore dériver sur les mouvements rapides ou les angles extrêmes ; vérifiez chaque clip.
- La disponibilité et les tarifs varient selon la surface — les niveaux Flow, app Gemini et API diffèrent, et Vertex AI expose certaines capacités en préversion payante.
Aucune de ces limites n'est une raison d'éviter la fonctionnalité ; ce sont des raisons de planifier délibérément vos trois ingrédients et de contrôler la sortie.
Comment cela s'intègre à un flux Veo 3.1
Ingredients to video est l'un des trois modes pilotés par l'image que vous utiliserez selon la tâche :
- Utilisez l'image de référence unique quand vous n'avez qu'un seul sujet à verrouiller. Commencez par le flux d'image de référence.
- Utilisez frames to video quand vous avez un début et une fin définis et voulez une transition. Le guide frames to video le parcourt de bout en bout.
- Utilisez ingredients to video quand vous combinez plusieurs éléments distincts en une nouvelle scène.
Beaucoup de projets réels utilisent les trois : construire personnages et accessoires comme ingrédients, générer le plan central, puis utiliser frames to video pour une transition nette vers le temps suivant, et Extend pour allonger la séquence. Vous pouvez exécuter cela sur les surfaces de Google ou via veo3ai.io au sein d'un seul pipeline.
Erreurs courantes à éviter
Quelques schémas causent la plupart des résultats décevants d'ingredients, et tous se corrigent facilement une fois que vous savez quoi surveiller.
Images de référence encombrées. Si votre photo de personnage comporte aussi un arrière-plan fort, une deuxième personne ou un logo voyant, Veo 3.1 ne sait pas quelle partie est l'« ingrédient ». Recadrez serré pour que chaque image représente clairement un élément.
Un prompt qui ignore les images. Téléverser trois références puis écrire un prompt générique comme « une scène cinématographique » gaspille toute la fonctionnalité. Le prompt doit nommer les images et attribuer des rôles.
Éclairages contradictoires. Un sujet pris en lumière de studio plate, déposé dans une scène nocturne sombre, paraîtra collé. Choisissez des ingrédients dont l'éclairage concorde déjà à peu près, ou décrivez explicitement l'éclairage voulu.
Surcharge des emplacements. Trois références qui se battent toutes pour le rôle principal donnent une bouillie. Souvent, deux ingrédients forts et complémentaires donnent un résultat plus net et plus maîtrisable.
Sauter l'itération sur l'entrée. Quand un clip dérive, le réflexe est de régénérer avec la même configuration. Le meilleur geste est souvent de remplacer par une image de référence plus nette ou de resserrer une ligne du prompt.
FAQ
Combien d'images de référence ingredients to video peut-il utiliser dans Veo 3.1 ? Jusqu'à trois. Chacune peut contrôler un élément différent — sujet, objet ou scène/style — et vous les ordonnez par priorité quand elles se concurrencent.
Ingredients to video diffère-t-il du téléversement d'une seule image de référence ? Oui. La référence unique verrouille un seul sujet ; ingredients compose plusieurs éléments distincts (personnage + objet + scène) en un clip. Ils résolvent des problèmes différents.
Ingredients to video inclut-il l'audio ? Oui. La mise à jour de Veo 3.1 a ajouté un son synchronisé natif et le dialogue, de sorte qu'une génération ingredients peut inclure du son dans la même passe.
Puis-je faire des vidéos verticales ? Oui. Veo 3.1 a ajouté un format vertical natif 9:16 pour ingredients, optimisé pour les plateformes mobiles comme TikTok, Reels et Shorts, en plus du 16:9 standard.
Où est-ce disponible ? Google Flow, l'app Gemini, Google Vids, YouTube, ainsi que de façon programmatique via l'API Gemini et Vertex AI.
Quelle est la durée de chaque clip ? Chaque génération produit un clip de 8 secondes. Pour du contenu plus long, utilisez les fonctions Extend et d'extension de scène de Veo 3.1 pour garder les personnages cohérents sur des segments connectés.
Conclusion
Veo 3.1 ingredients to video est le moyen le plus direct de contrôler en même temps qui, quoi et où dans un clip IA. En donnant au modèle jusqu'à trois images de référence — une pour le personnage, une pour l'objet, une pour la scène ou le style — et en écrivant un prompt qui associe chaque image à son rôle, vous obtenez des plans composés et cohérents que les prompts texte et l'image de référence unique ne peuvent tout simplement pas produire. Cela se distingue de frames to video, qui fait le pont entre deux images clés, et de la référence unique, qui ne verrouille qu'un seul sujet. Planifiez vos trois ingrédients, préparez des entrées propres, promptez par rôle et contrôlez chaque clip. Puis essayez le flux vous-même avec Veo 3.1 sur veo3ai.io et transformez vos photos de référence en une scène qui bouge.
Related Articles
Continue with more blog posts in the same locale.
Quelle est la durée des vidéos Veo 3.1 ? Limites de longueur (2026)
Les clips Veo 3.1 plafonnent à 8 secondes par génération, mais l'extension permet d'atteindre ~148 secondes. Durées natives, Fast vs Quality, règles vidéo-à-vidéo et FAQ.
Read article
Prompts vidéo au ralenti pour Veo 3 (2026) : slow-motion cinématographique et rampes de vitesse
Maîtrisez le ralenti dans Veo 3 : vocabulaire de prompts, 7 prompts prêts à l'emploi, rampes de vitesse, gestion du son et erreurs à éviter.
Read article
Prompts vidéo POV pour Veo 3 : générer des plans à la première personne (2026)
Comment écrire des prompts POV pour Veo 3 pour une vidéo immersive à la première personne : formule en 5 parties, 12 exemples prêts à l'emploi, son synchronisé et workflow vertical pour TikTok et Shorts.
Read article